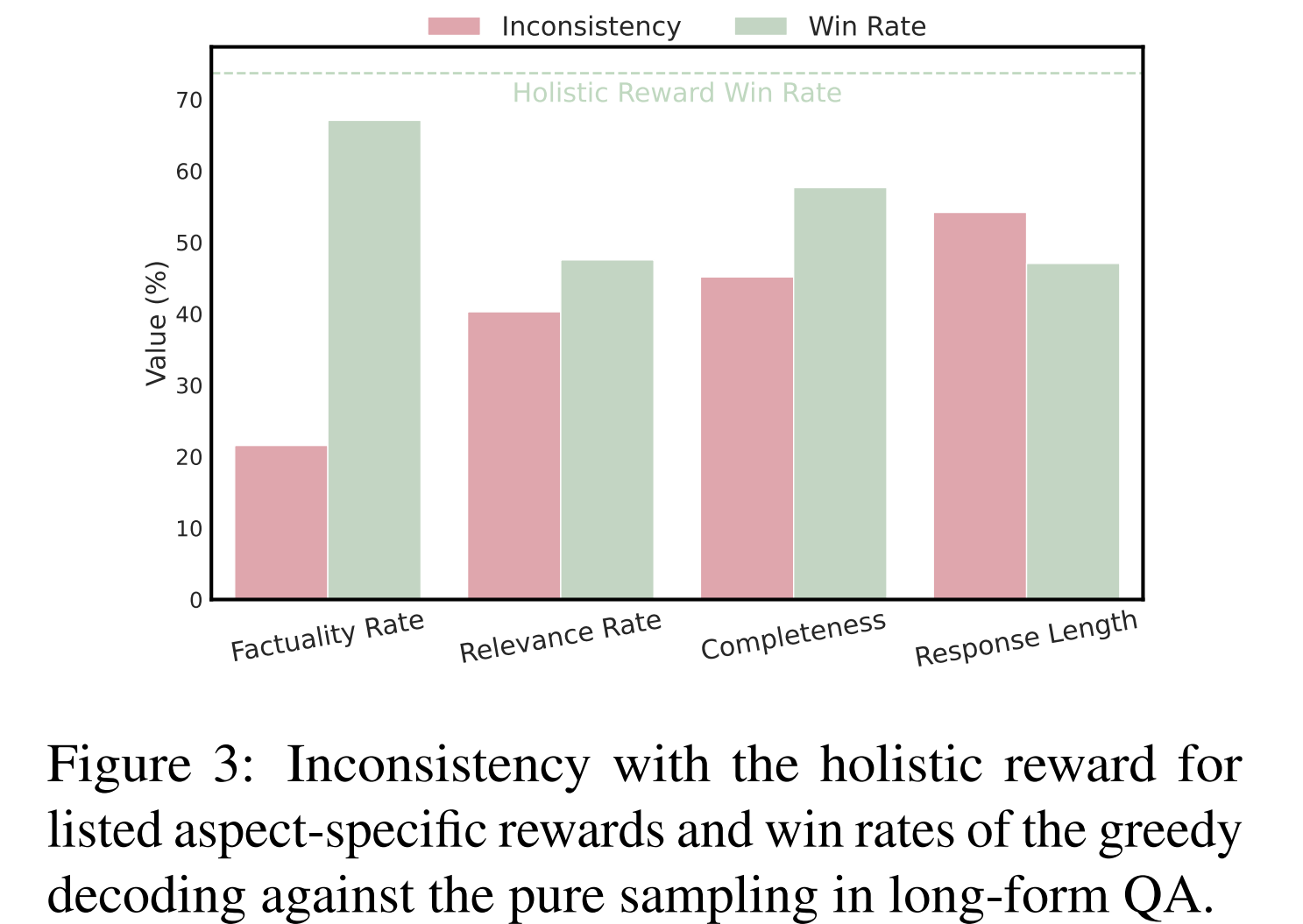
We introduce ALaRM, the first framework modeling hierarchical rewards in reinforcement learning from human feedback (RLHF), which is designed to enhance the alignment of large language models (LLMs) with human preferences.
The framework addresses the limitations of current alignment approaches, which often struggle with the inconsistency and sparsity of human supervision signals, by integrating holistic rewards with aspect-specific rewards. This integration enables more precise and consistent guidance of language models towards desired outcomes, particularly in complex and open text generation tasks. By employing a methodology that filters and combines multiple rewards based on their consistency, the framework provides a reliable mechanism for improving model alignment.
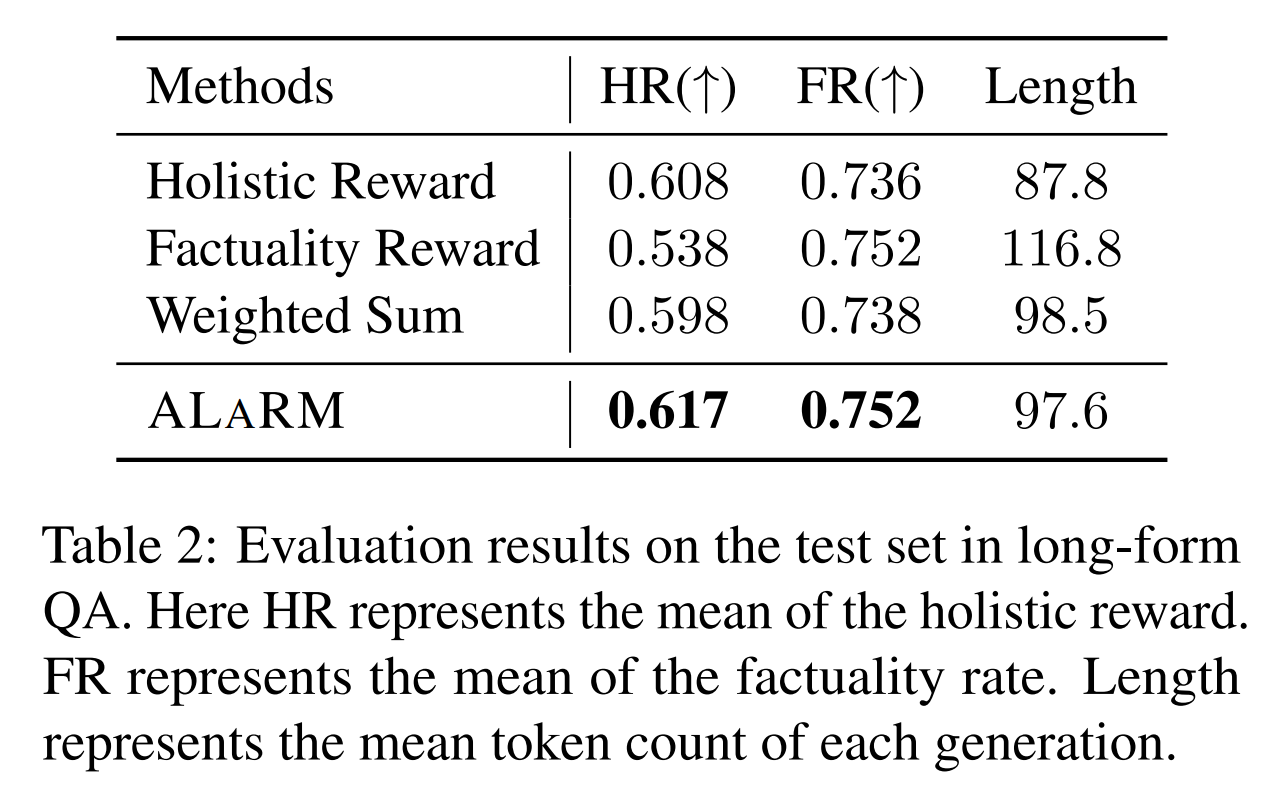
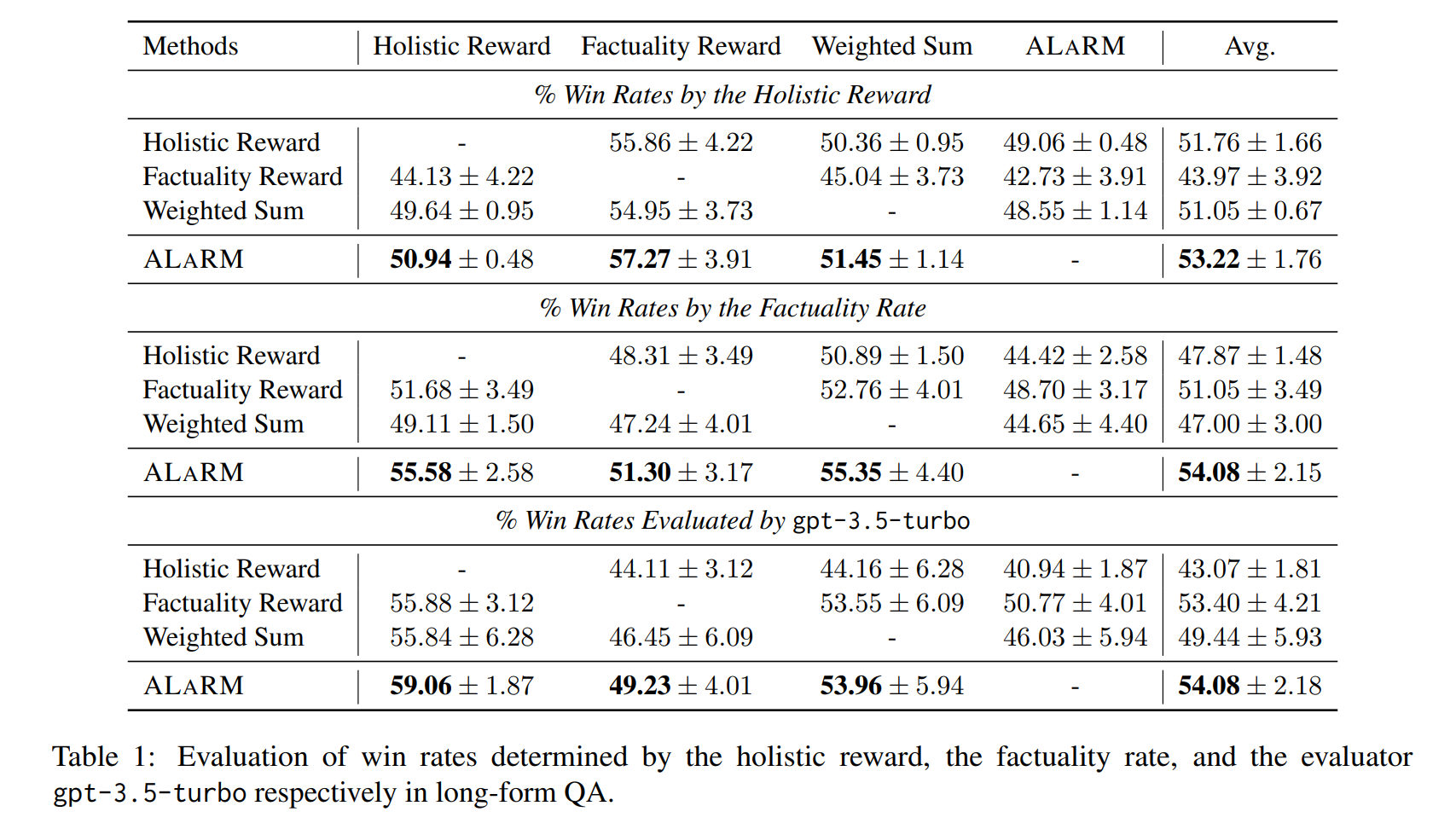
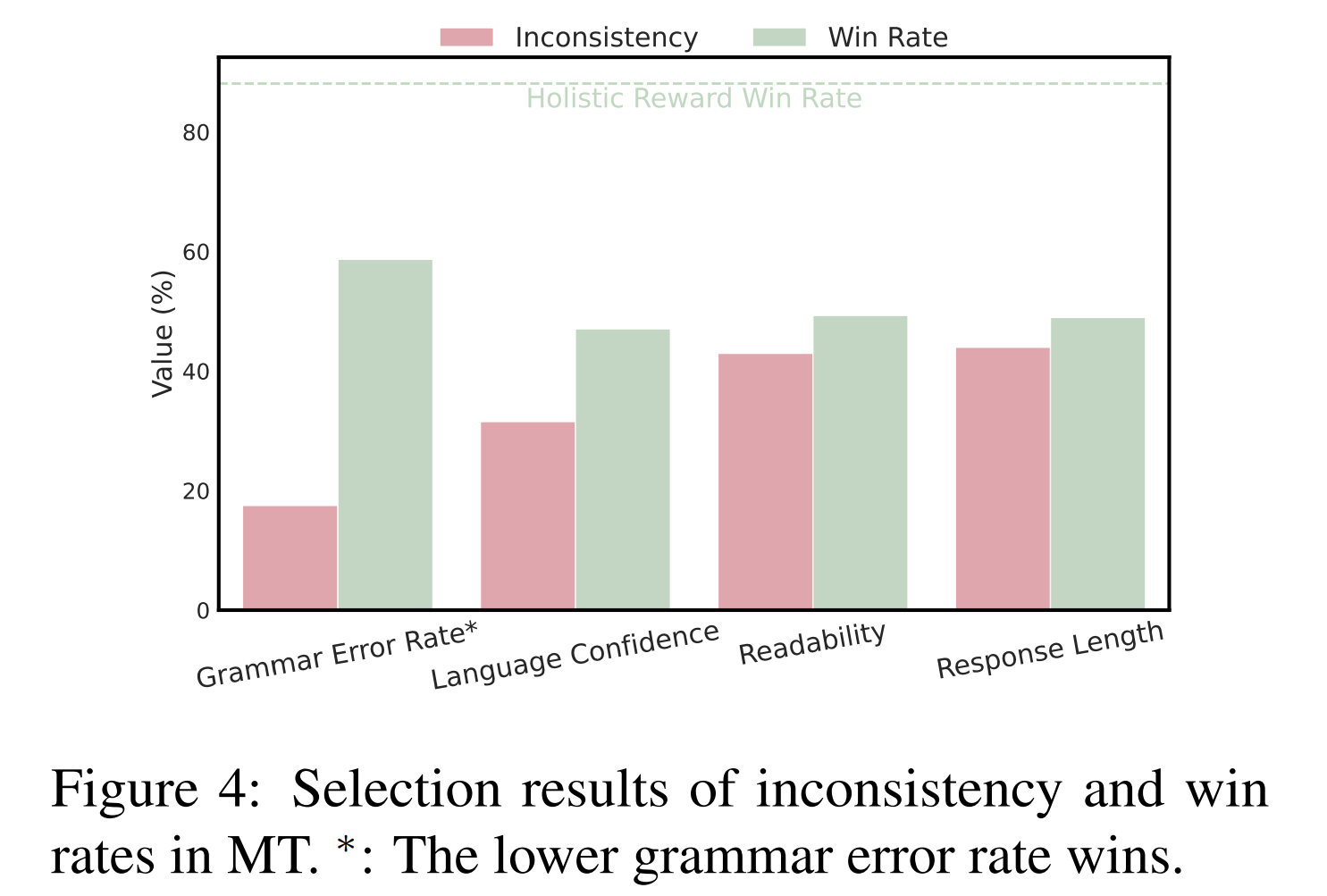
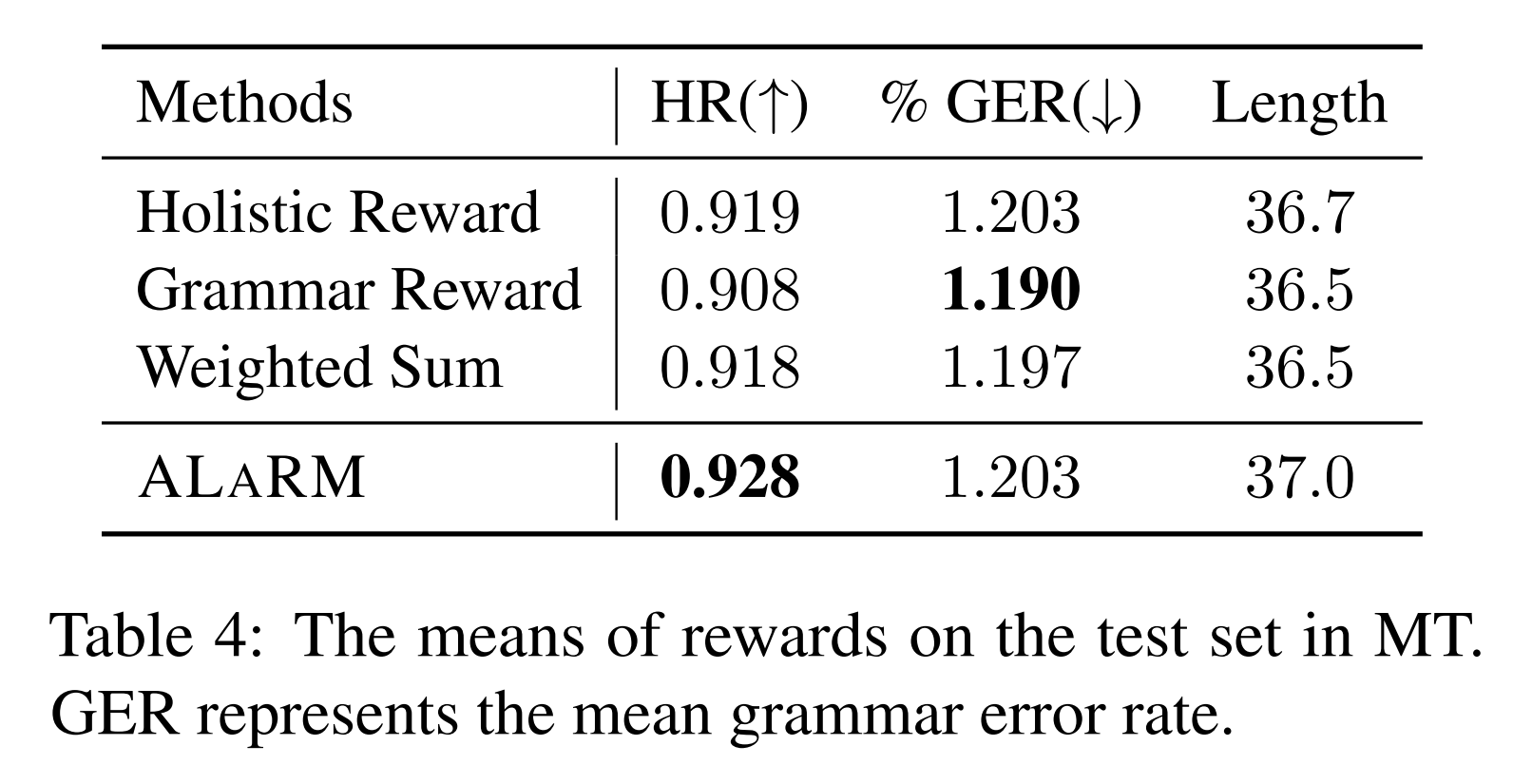
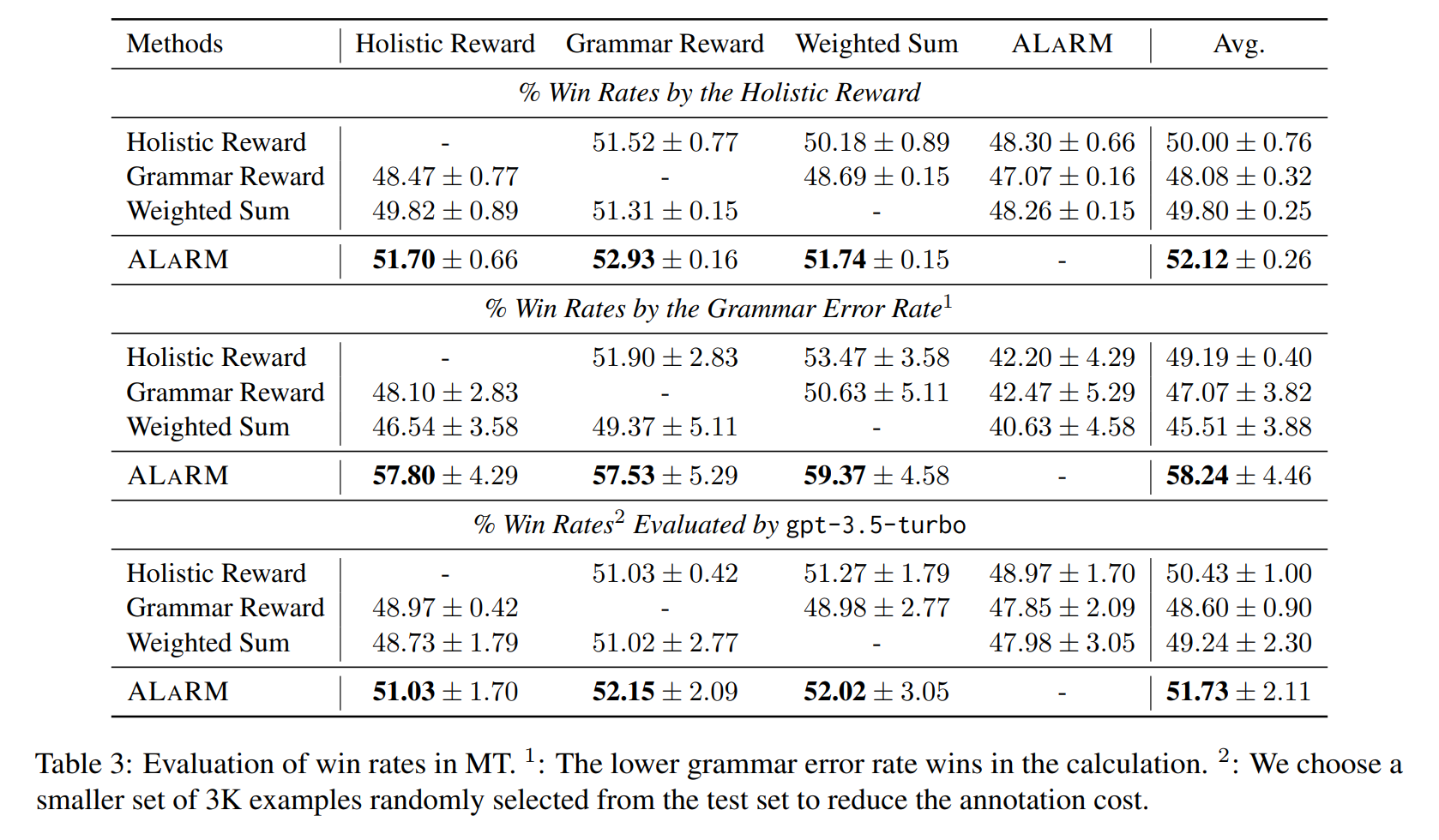
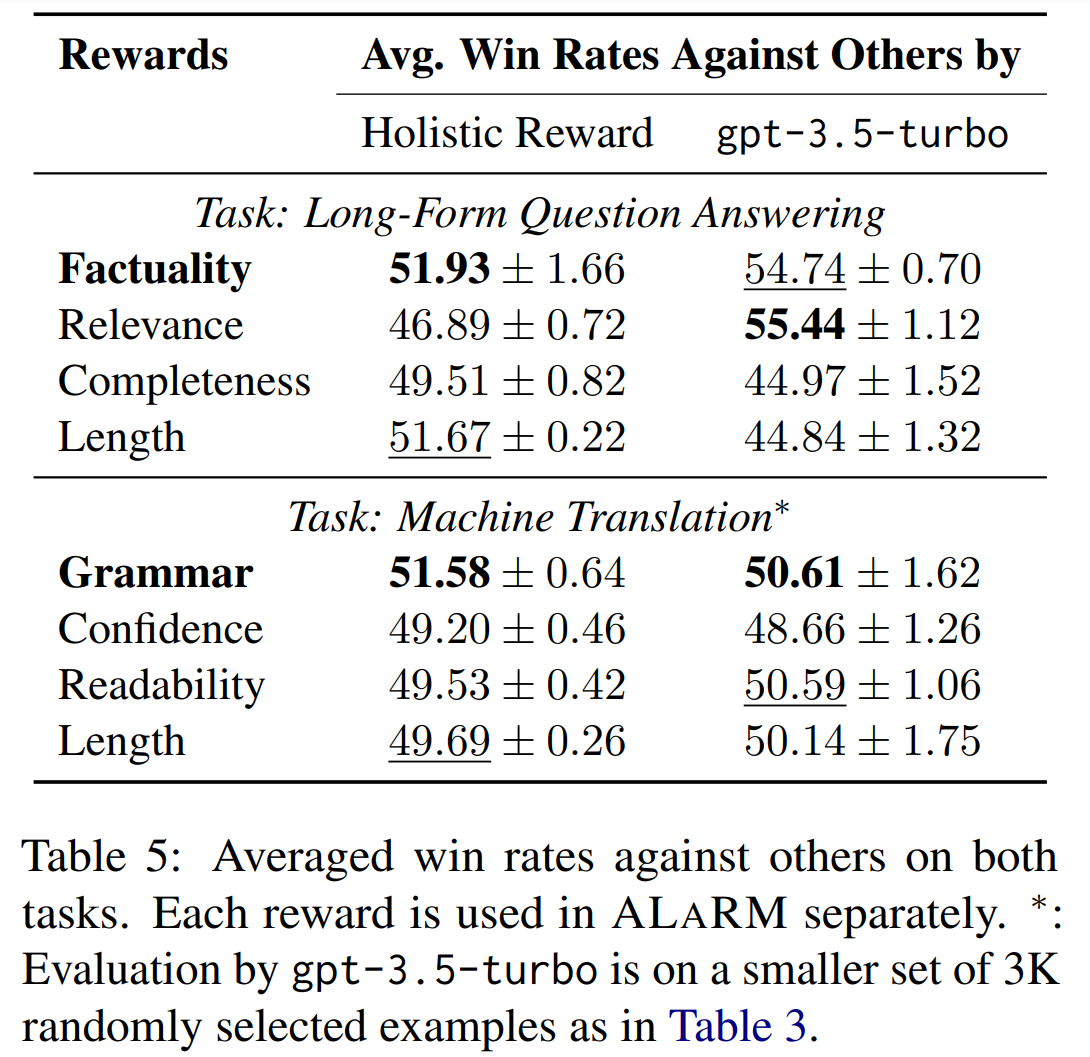
We validate our approach through applications in long-form question answering and machine translation tasks, employing gpt-3.5-turbo for pairwise comparisons, and demonstrate improvements over existing baselines. Our work underscores the effectiveness of hierarchical rewards modeling in refining LLM training processes for better human preference alignment.